热门文章
联系我们
联系人:寇先生
微信公众号:

SAP HANA Smart Data Access(三)——如何利用SDA通过Hive访问Hadoop数据
知识分享不易,转载请标注来源:http://www.blenderkou.top/contents/2/4240.html 版权申明:欢迎转载,但请注明出处。 一些博文中的参考内容因时间久远找不到来源了没有注明,如果侵权请联系我删除。
转载,原文链接:
https://blogs.sap.com/2014/03/17/sap-hana-smart-data-access-三-如何利用sda通过hive访问hadoop数据/
引言
本系列上一篇文章以Oracle数据源为例介绍了如何在SAP HANA服务器端安装和配置SDA数据源驱动。SDA支持的大多数数据源都是数据库,所以安装与配置过程大致相同。但是,Hadoop数据源相对其他SDA数据源较为特殊,作为一个分布式数据处理平台,Hadoop的数据通常存储在分布式文件系统HDFS或NoSQL数据库HBase中,这二者都不直接支持ODBC协议。Hadoop家族的Hive和Impala等数据查询工具能够以SQL方式操作存储在HDFS或HBase中的数据,并支持通过ODBC访问数据。因此,SDA可以通过Hive或Impala访问Hadoop数据源。本文讲解SDA如何利用Hive访问存储在HDFS中的数据。
部署Hadoop和Hive
SAP HANA官方支持的Hadoop版本是Intel Distribution for Apache Hadoop version 2.3(包括Apache Hadoop version 1.0.3和Apache Hive 0.9.0)。虽然官方的支持列表中只有Intel Distribution for Apache Hadoop(IDH), 但是通过实验验证得知,普通的Apache版Hadoop和Hive同样可以通过SDA进行访问。本文实验使用三个结点组成的Hadoop集群,Hadoop和Hive的版本是:Apache Hadoop 1.1.1和Apache Hive 0.12.0 。关于Hadoop和Hive的安装和配置在此就不多说了,有兴趣的读者请参考相关资料。
部署好Hadoop和Hive后,我们需要准备一些数据,实验使用的是一张用户信息表。先介绍一下表结构:
列名 | 数据类型 | 描述 |
USERID | VARCHAR(20) | ID号 |
GENDER | VARCHAR(6) | 性别 |
AGE | INTEGER | 年龄 |
PROFESSION | VARCHAR(20) | 职业 |
SALARY | INTEGER | 工资收入 |
Hive支持从文件导入数据,本文实验从CSV(Comma Separated Value)文件导入数据到表格中。我们先在Hive Shell中用以下语句创建一张表。
create table users(USERID string, GENDER string, AGE int, PROFESSION string, SALARY int)
row format delimited
fields terminated by ‘\t’;
然后,将CSV中的数据导入users表中:
load data local inpath ‘/input/file/path’
overwrite into table users;
此处是从本地文件系统导入数据,Hive同样支持从HDFS导入数据。本文实验数据量为1000000行。导入完成之后,select count(*) from users查看记录数,结果如下图:
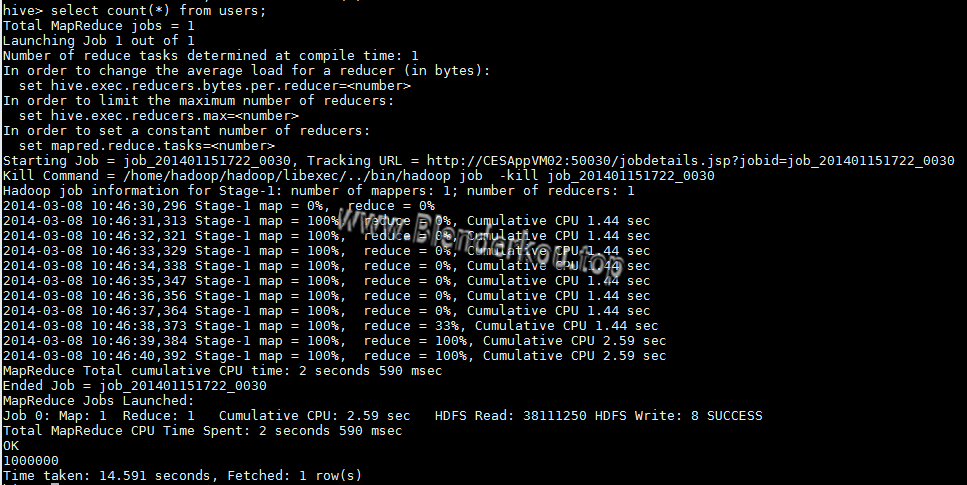
从上图可以看到,Hive调用了MapReduce框架进行数据查询,count一百万行数据用了14.6秒。再查询前10条记录:
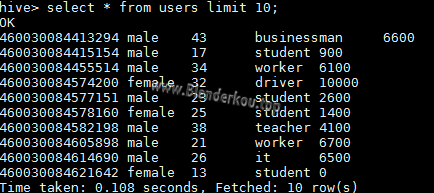
查询10条语句用了0.1秒。
安装与配置HiveODBC驱动
和其他SDA数据源一样,安装HiveODBC驱动之前需要在SAP HANA服务器端安装unixODBC驱动管理器。HiveODBC需要unixODBC-2.3.1或以上版本。关于unixODBC的安装,详见参考文献[2]。装好驱动管理器后再安装HiveODBC驱动程序。如文献[2]中介绍,SAP官方推荐使用Simba Technologies提供的HiveODBC驱动。
1. 下载Simba HiveODBC驱动包后将其解压至指定文件夹,
进入 /driver_install_dir/samba/hiveodbc/lib/64/(如果是32位系统则此处的64用32代替)
文件夹,确认存在驱动文件libsimbahiveodbc64.so。
2. 以<sid>adm用户登陆SAP HANA服务器;
3. 用HDB stop命令停止SAP HANA;
4. 将文件/driver_install_dir/simba/hiveodbc/Setup/simba.hiveodbc.ini
拷贝到<sid>adm的家目录下:
cp /driver_install_dir/simba/hiveodbc/Setup/simba.hiveodbc.ini ~/.simba.hiveodbc.ini
5. 用vim打开~/.simba.hiveodbc.ini文件;
6. 如果有一行是DriverManagerEncoding=UTF-32,将其改为UTF-16;
7. 确认ErrorMessagePath=/driver_install_dir/simba/hiveodbc/ErrorMessages,
如果不对则更改过来;
8. 注释掉ODBCInstLib=libiodbcint.so这一行,再加上一行:ODBCInstLib=libodbcinst.so;
9. 编辑<sid>adm家目录下的.odbc.ini文件,加入hive的DSN,hive端口默认为10000,如:
[hive1]
Driver=/driver_install_dir/simba/hiveodbc/lib/64/libsimbahiveodbc64.so
Host=<IP>
Port=10000
10. 在$HOME/.customer.sh下设置以下环境变量:
export LD_LIBRARY_PATH=
$LD_LIBRARY_PATH:/driver_install_dir/simba/hiveodbc/lib/64/
export ODBCINI=$HOME/.odbc.ini
11. 用isql检查是否可成功连接到Hadoop:isql –v hive1
12. 如果连接成功,启动SAP HANA。
创建HIVE数据源
在确认用isql能够成功连接hive后,用文献[1]中介绍的方法在HANA Studio中创建远程数据源。注意,使用SQL语句创建数据源时用ADAPTER关键字指定HIVEODBC,图形化界面创建时,Adapter Name选择HADOOP(ODBC)。
Hive数据源创建成功后,查看远程数据源中的表,如下图所示:

查询Hive虚表
使用文献[1]介绍的方法添加一张虚表HiveUsers对应Hive中的users表,在SQL Editor中count该虚表,结果如下:
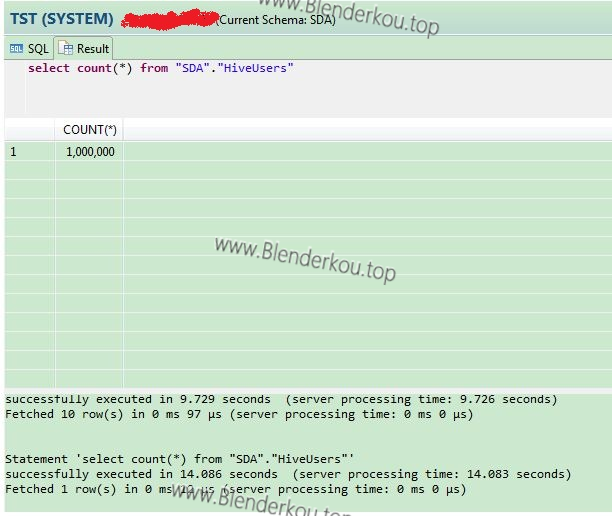
以上结果显示,count表HiveUsers用了14.1秒,和在Hive端count相差无几。由此可以看出,对于网络数据传输较小的操作,用SDA操作远程数据源和远程数据源本地操作效率相当;同时,以上结果也说明Hive的数据查询效率是较低的,它适合批处理任务,而对实时性要求较高的应用不适合使用Hive。
总结
本文通过一个简单的数据查询示例讲解了SDA如何通过Hive访问存储在Hadoop中的数据。Hive是为Hadoop提供SQL接口的工具之一,从实验结果可看出,Hive的查询效率并不算高,后续文章将介绍SDA如何通过其他的Hadoop数据查询工具(如Impala)操作Hadoop数据。
想获取更多SAP HANA学习资料或有任何疑问,请关注新浪微博@HANAGeek!我们欢迎你的加入!
转载本文章请注明作者和出处http://scn.sap.com/community/chinese/hana/blog/2014/03/17/sap-hana-smart-data-access-%E4%B8%89-%E5%A6%82%E4%BD%95%E5%88%…,请勿用于任何商业用途。
参考文献
SAP HANA Administrator Guide 6.1.1章节。

扫描二维码,关注我的公众号,第一时间获取文章!
知识分享不易,转载请标注来源:http://www.blenderkou.top/contents/2/4240.html 版权申明:欢迎转载,但请注明出处。 一些博文中的参考内容因时间久远找不到来源了没有注明,如果侵权请联系我删除。


上一篇
如何设置SAP Business One (SAP HANA 版本)水晶报表的数据源
下一篇
SAP HANA Smart Data Access(二)——SDA数据源驱动的安装与配置

